Hyper Analyzer
Suponha que um conjunto de dados seja composto por três colunas, duas delas “agrupáveis” (ou seja, uma coluna em que GROUP BY é aplicável) e uma “agregável” (ou seja, usada em funções SUM, COUNT, AVG na SELECT de uma cláusula SQL). Este conjunto de dados seria explorado como o cubo 3D na figura 3.5(b). Em contraste, a visualização OLAP tradicional trata esses conjuntos de dados como cubos desdobrados, conforme mostrado na figura 3.5(a), ou seja, entendimento prejudicado pela perda de relações espaciais. Adicionar colunas “agrupáveis” e “agregáveis” ao conjunto de dados se transforma em um conjunto de dados multidimensional. Eles se comportam como tesseratos desdobrados (figura 3.5(c)) quando os utilizadores analisam cada conjunto de dados em sequência. Em contraste, combinar o conjunto de dados para visualizações simultâneas mapeia para a figura 3.5(d).
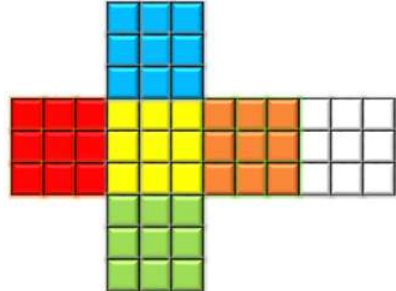
Figura 3.5(a)

Figura 3.5(b)

Figura 3.5(c)

Figura 3.5(d)
O HyperAnalyzer lida com essas questões oferecendo formas complementares de visualização das informações, integrando propostas de interação e o mantra de Shneiderman para permitir que o utilizador escolha a estratégia de visualização que melhor se adapta às suas necessidades. Primeiro, o utilizador prepara os dados delimitando o número de colunas, transpondo, adicionando cálculos personalizados, gerando gráficos e criando novas faces com esses dados transformados. Em seguida, o utilizador faria uma sequência (por exemplo, para uma apresentação de slides), compararia lado a lado, usaria a técnica de “depth and surface” e assim por diante. A Figura 3.16 mostra um conjunto de dados de 3 colunas na visualização padrão inicial: (a) contém uma tabela de resumo e um gráfico de pizza gerados por rótulo de coluna e total da coluna; (b) uma tabela de resumo e gráfico de barras gerado por rótulo de linha e total de linha; (c) a tabela inteira dividida em duas faces.
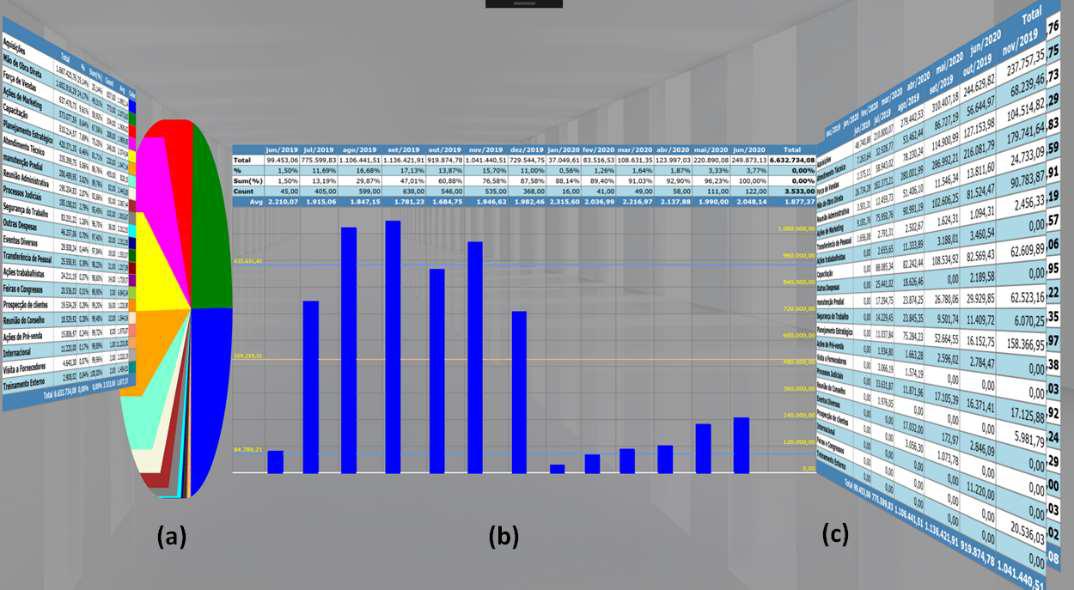
Conforme mostrado na figura 3.17, o relatório de cubo dividido colocado em uma visualização lado a lado destaca “colunas externas”. Assim, as colunas externas geram o gráfico de pizza na figura 3.16(a). Aplicando os mesmos critérios para linhas, temos o gráfico de barras da figura 3.16(b). Portanto, as linhas e colunas externas são a “Visão Geral” e devem aparecer primeiro.
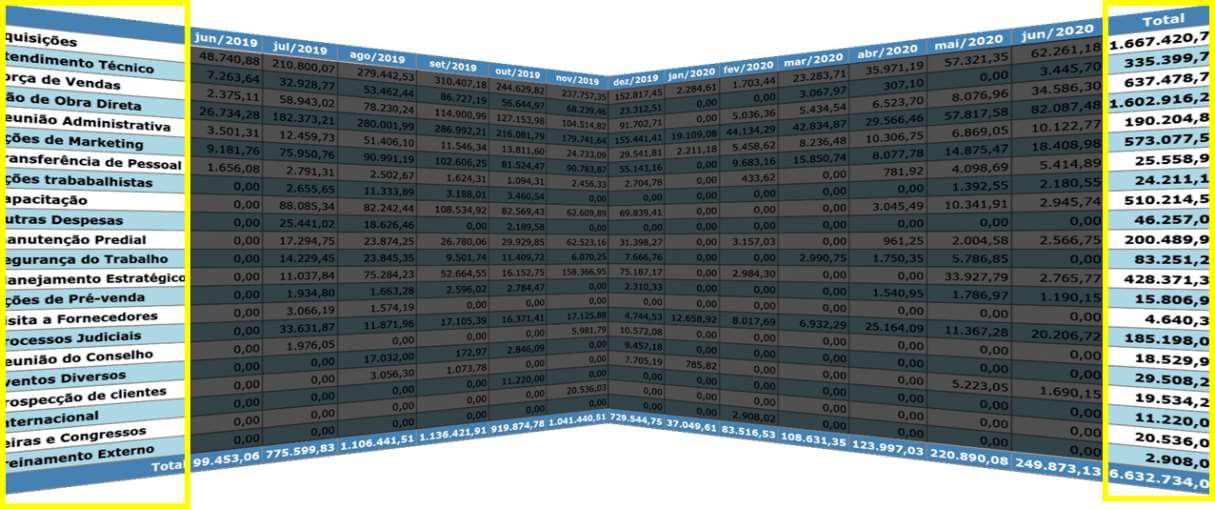
A escolha de um gráfico de pizza para colunas e um gráfico de barras para linhas foi apenas uma preferência pessoal. O gráfico de pizza destaca a participação de cada coluna no resultado, ou seja, trata as colunas como categorias. No entanto, os dados de linha são temporais e o gráfico de barras ilustra como os números mudam ao longo do tempo. No entanto, alguém pode considerar o oposto como uma abordagem melhor: um gráfico de pizza para indicar o progresso ao longo do tempo e um gráfico de barras para comparar a participação nas categorias. Caso contrário, usar o mesmo tipo de gráfico facilita a comparação de dados de linha e coluna. Todos esses cenários são facilmente alcançados substituindo o conteúdo das faces ou criando faces. A partir dos insights fornecidos pelas faces de visão geral, é possível gerar visualizações segmentadas como “zoom and filter”. Por exemplo, na figura 3.18, (a) mostra uma revisão trimestral (linhas), enquanto (b) mostra três categorias selecionadas. Os cálculos são feitos apenas para o conjunto de dados selecionado.
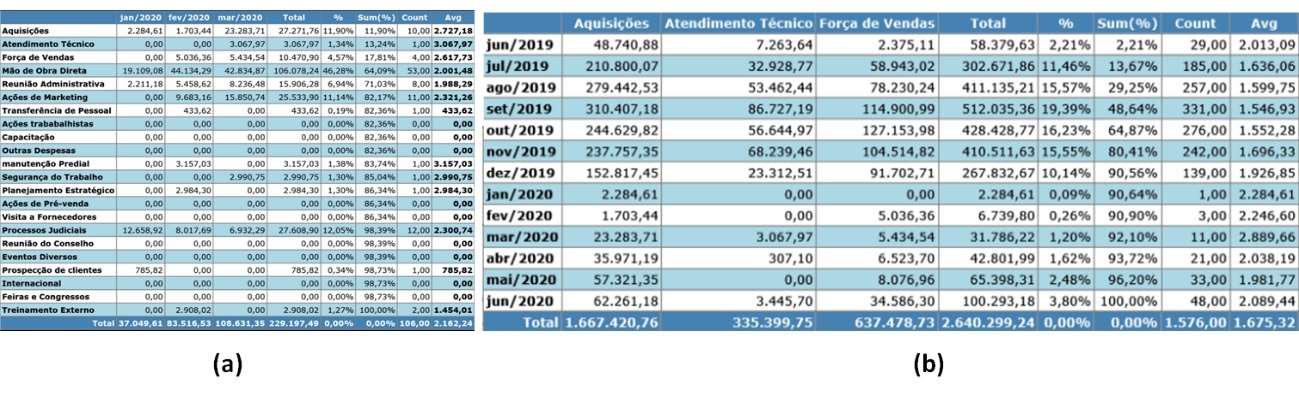
(a) Filtro por revisão trimestral
(b) Filtro por categoria.